
TL;DR
Most SaaS AI assistants fail not because the language model is wrong, but because there is no governed layer between what the model decides and what executes in production. The fix is a clean three-layer architecture: a conversation layer (API Gateway, Lambda, Bedrock Guardrails), a reasoning layer (Amazon Bedrock, with retrieval via Bedrock Knowledge Bases or your own vector store), and an execution layer (AWS Step Functions as the deterministic control plane that governs what the model is allowed to do). Security depends on propagating JSON Web Token (JWT) identity through every downstream operation, so the assistant acts as the requesting user, never under an elevated service credential. Latency is managed by returning a job ID immediately and pushing updates asynchronously. Observability means logging the full decision chain, not just infrastructure metrics, into OpenSearch via Amazon Data Firehose.
The demo that passed every test, except the real one
A product manager walks through a demo in sprint review. The AI assistant surfaces the right customer data, answers support questions fluently, and summarizes a complex account history in two sentences. The room is impressed. The CEO leans forward. Someone screenshots the demo before it finishes. By Monday morning there is a Slack message from the CTO: ship it for Q3.
Three months later, still not shipped. Or worse, shipped and quietly rolled back after a support agent pulled ticket history from a different customer’s account. Not a platform failure. A missing ‘tenantId’ scope on a retrieval query. The kind of oversight that is invisible in a single-tenant demo and catastrophic under real multi-tenant load. Entirely preventable, if the architecture had been designed to enforce it.
Two conversations happen inside every SaaS organization building with AI right now. The first is the executive briefing where the demo lands and the roadmap gets rewritten on the spot. The second is the engineering post-mortem three weeks later, where the team is working out why tenant isolation broke the moment the model touched production data, why latency became indefensible under real concurrent load, and why nobody can clearly answer: what is this thing permitted to do?
The gap between those two conversations is not a capability problem. The model is capable. The prompts work. What nobody designed is the governed layer that determines what the assistant is allowed to do, how it executes safely, and how the team explains its behavior when something goes wrong.
That gap is what this piece is about.
AWS defines AI assistants as systems that integrate with an organization’s digital workflows and take over administrative and operational tasks, not systems that answer questions about those workflows. That distinction matters. It is exactly where most SaaS implementations fall short.
The execution layer nobody builds
Most teams building AI assistants focus on two things: understanding what the user asked and generating a useful response. Both are well-supported problems. Amazon Bedrock handles the language model. Retrieval can be handled through Bedrock Knowledge Bases for a fully managed Retrieval Augmented Generation (RAG) pipeline, or through OpenSearch Serverless and Aurora pgvector if you need more control over chunking, indexing, and hybrid search.
What almost nobody designs is the third thing: the governed execution layer that takes what the model proposed and runs it against your system safely, with permissions enforced, retries handled, and a rollback path available when something fails partway through.
Most prototypes stop at the response. Production starts when you design what happens after the model has spoken.
Before you write a line of code, decide whether your assistant is answering questions, collecting input, completing operations, or initiating actions based on triggers. Each mode has different architecture requirements, and most teams discover this too late.
What breaks production AI assistants
The same problems show up on nearly every engagement. They are predictable, and they are all visible before launch if you know where to look.
1. The permission model breaks when the LLM touches production data
In a multi-tenant B2B SaaS product, every read and write carries identity context: which tenant, which user, what their role permits. Most prototypes bypass this entirely. The model runs under a shared service credential with broad read access because that was the path of least resistance on a Friday afternoon. In a single-tenant demo, invisible. Under real multi-tenant load, it is the exact scenario that gets rolled back at 11pm after a customer reports seeing another organization’s record.
Implementation note: Extract tenantId and userId from JWT claims at the API Gateway authorizer stage. Pass both as execution context into Lambda via the event payload. Step Functions receives this context as input and carries it through each state, making it available at every resource call. Aurora row-level security policies keyed on tenantId provide the final guarantee at the data layer. If you are using Bedrock Knowledge Bases, apply metadata filtering on tenantId at query time to scope retrieval to the requesting tenant.
The assistant acts as the requesting user. Nothing more.
2. No deterministic layer between “the model decided” and “the action happened”
LLMs are probabilistic. Given the same prompt twice, they can return structurally different outputs. In a chatbot, that variability is largely harmless. In an assistant that triggers real workflows, it is not. Consider: a customer support agent asks the assistant to “look into why this account’s usage spiked last month.” The model interprets that as an action request, confidently proposes a billing tier downgrade, and nothing between that proposal and your billing API catches the mismatch between what the user asked and what the model decided to do. The model does not know it is wrong. It just executes.
The fix: a Lambda task within an AWS Step Functions state machine validates the schema and checks permissions before any action proceeds. Step Functions then executes deterministically, sequencing steps, handling retries with exponential backoff, and routing to a human approval gate if the action exceeds a defined risk threshold. The model never touches production resources directly.
AWS has been building toward managed guardrails for this kind of problem. Bedrock AgentCore, now generally available, provides runtime infrastructure including policy controls (via AgentCore Policy and the Cedar policy language) that intercept tool calls in real time. For teams further along the maturity curve, AgentCore can handle some of the governance that you would otherwise wire up manually. But the architectural principle holds regardless of which layer enforces it: a deterministic gate between model output and system action is non-negotiable.
Implementation note: Use Bedrock structured outputs with strict: true on the tool definition to constrain LLM output to a strict action schema: { actionType, resourceId, tenantId, parameters }. This enforces schema compliance at the model layer via constrained decoding, not as a prompt instruction but as a hard constraint on token generation. Step Functions receives the validated object as input. Free-text LLM output never enters the execution path. Note: As of early 2026, Amazon Bedrock supports constrained tool definitions via the Converse API, not all model providers on Bedrock support strict: true in the same way.
3. Latency turns a capable assistant into an unusable one
A typical Bedrock inference call sits between one and five seconds total response time under normal load. Complex prompts or high concurrency push toward eight to ten seconds. Chain intent classification, context retrieval, and action proposal together, and you are looking at twelve to twenty seconds of synchronous wait before the UI can respond. The demo ran fast because there was one user, a short context window, and no concurrency. Production is not a demo.
Implementation note: API Gateway returns { jobId, status: ‘accepted’ } immediately. Lambda publishes to EventBridge. Step Functions executes asynchronously. The client polls or subscribes to SSE for status updates. For conversational responses, use InvokeModelWithResponseStream and proxy the token stream through API Gateway response streaming (available for REST APIs since November 2025, via ResponseTransferMode: STREAM on the Lambda proxy integration). WebSocket API remains the right choice for multi-turn or bidirectional sessions. Never block the HTTP thread on LLM inference.
Design the async contract before you design the prompts. The UI state machine (pending, processing, complete, failed) is as important as the LLM state machine.
An AWS-native architecture that holds under production load
Everything described here is deployable today, inside your AWS account, using services most SaaS teams already have procurement coverage for. The architecture separates concerns across three explicit layers:
Conversation layer. API Gateway decodes JWT claims into tenant context. Lambda assembles the prompt. Bedrock Guardrails filters both inputs and outputs: denied topics, sensitive information (PII), and content filters covering harmful content categories, applied on the way in and on the way out.
Reasoning layer. Amazon Bedrock classifies intent and proposes a structured action. Retrieval is scoped to the requesting tenant, using Bedrock Knowledge Bases with metadata filtering for a managed RAG pipeline, or OpenSearch Serverless and Aurora pgvector where you need direct control over indexing and search. This layer produces a decision. It does not execute one.
Execution layer. Step Functions receives the structured action payload. A Lambda task validates it and checks permissions before execution proceeds. Step Functions then sequences steps, handles retries with exponential backoff, and routes to human approval for high-risk operations. This layer owns the safety guarantees.
These layers do not collapse into one. That separation is what makes the system governable, independently testable, and explainable when something unexpected happens in production. It is also what makes the second assistant faster to build: the execution layer is reusable infrastructure, not bespoke logic rebuilt for each new feature.
Three reference patterns
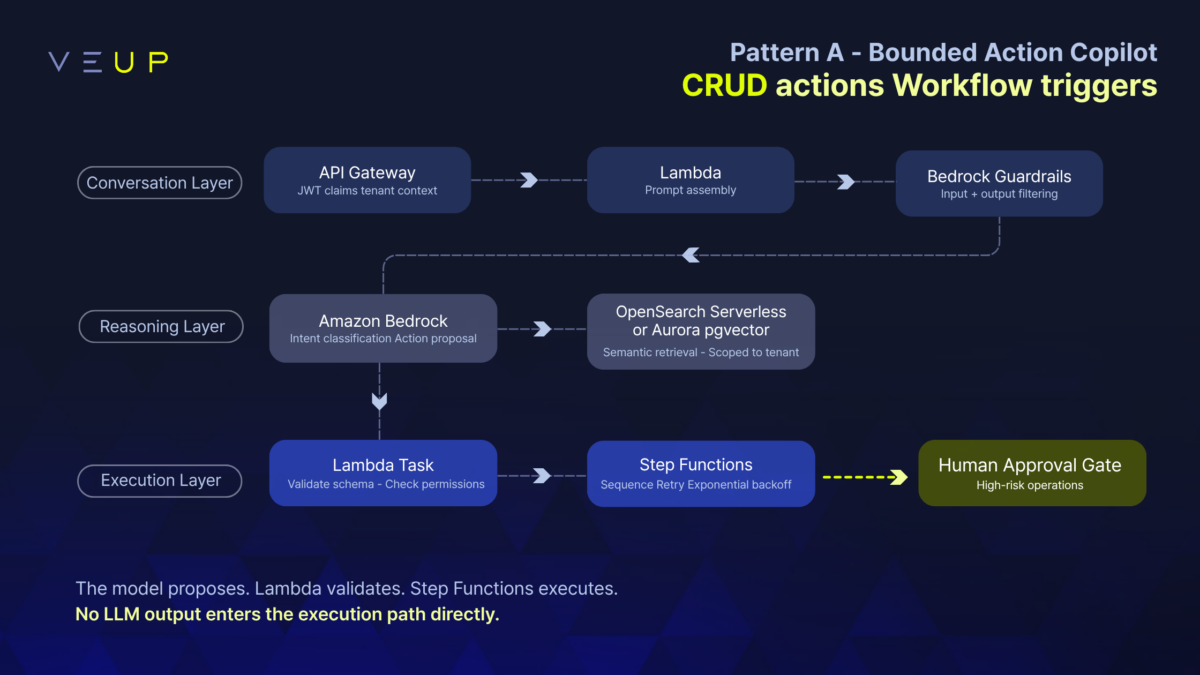
Pattern A: Bounded Action Assistant. Think of asupport operations tool where agents can update ticket status, pull customer configuration, or draft a response for human review. CRUD-style actions, pre-defined workflow triggers, narrow scope. The full three-layer architecture is in place from day one, even though the action set is small. Ship this first. The telemetry from real usage tells you where to expand.
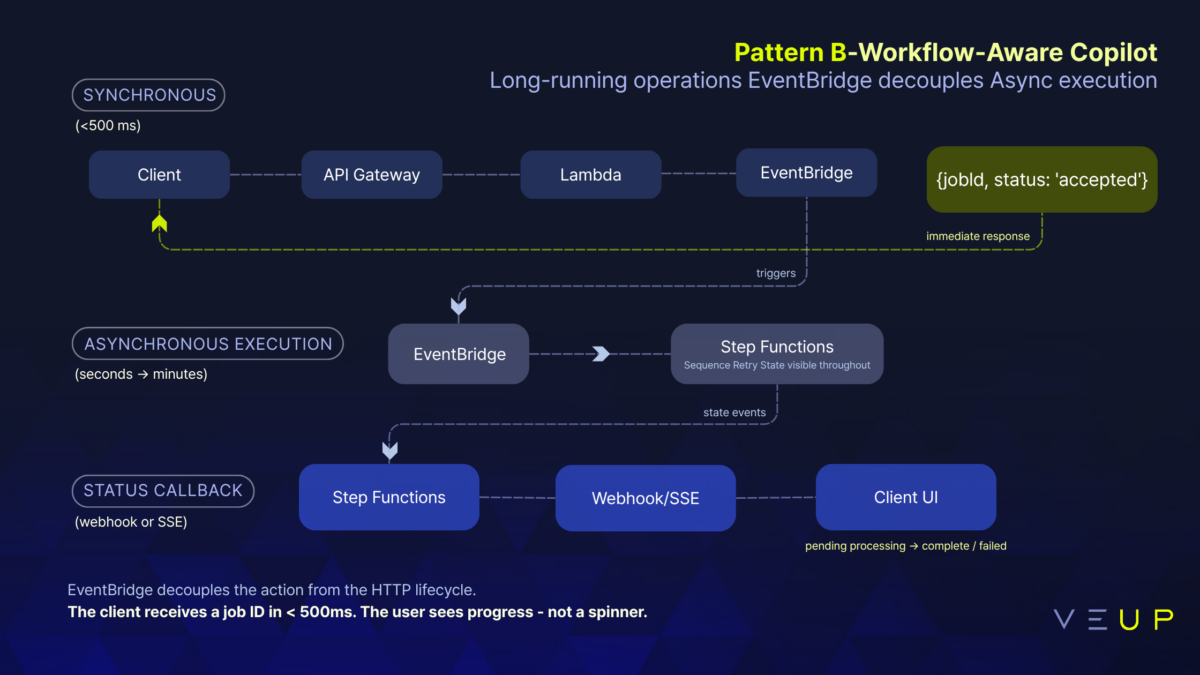
Pattern B: Workflow-Aware Assistant. For operations that cannot complete in a single request-response cycle. A compliance team member asks the assistant to regenerate a tenant’s audit report, which requires pulling data from three services, running validation, and producing a PDF. EventBridge decouples the action from the HTTP lifecycle. Step Functions executes asynchronously across minutes. The client gets a job ID immediately and updates via webhook or Server-Sent Events (SSE). The user sees progress, not a spinner.
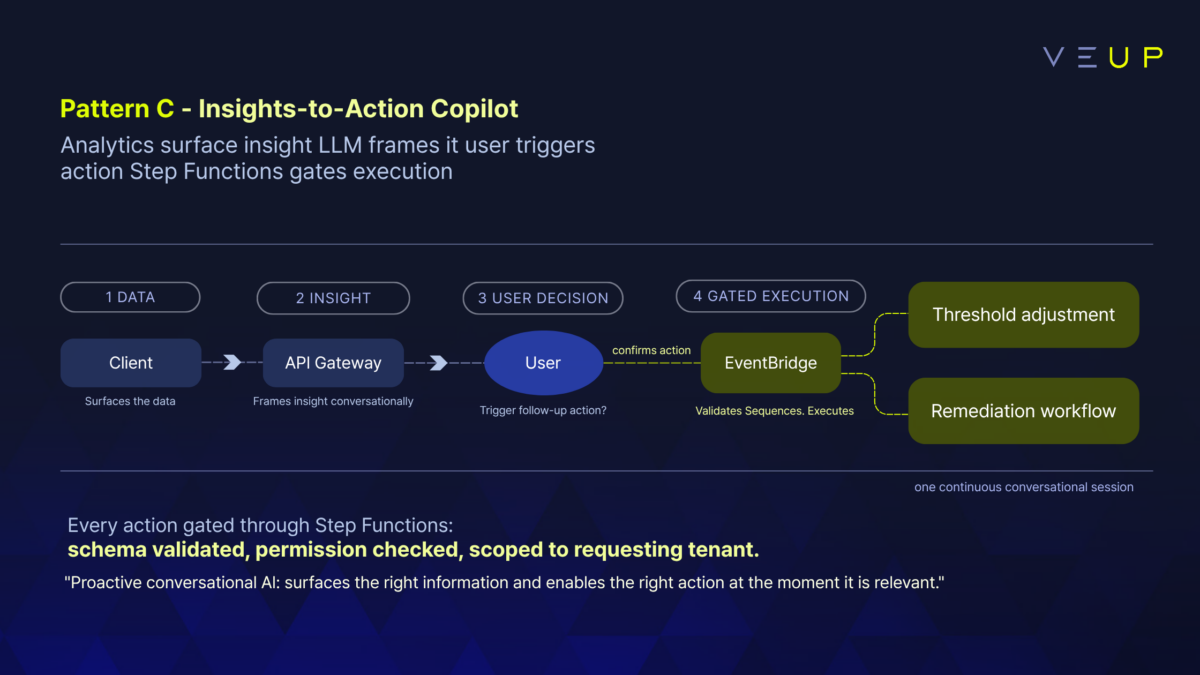
Pattern C: Insights-to-Action Assistant. A platform operations dashboard where Athena or Redshift surfaces a usage anomaly. The LLM frames the insight conversationally: “Tenant X’s API call volume is 4x the 90-day average, concentrated on the /export endpoint.” The user can trigger a follow-up action directly, adjusting a rate limit threshold or kicking off a remediation workflow, gated through Step Functions before anything executes. The insight and the action become one continuous interaction.
Where managed services fit. If you are early in your AI journey and do not need fine-grained control over retrieval or execution, start with Bedrock Knowledge Bases and AgentCore. They handle a meaningful portion of what you would otherwise wire up yourself: RAG ingestion, runtime isolation, policy enforcement, observability. You can decompose into custom infrastructure as your requirements sharpen. The three-layer separation described here is the mental model. Whether each layer is custom code or a managed service is an implementation decision, not an architectural one.
The real security conversations for SaaS CTOs
This conversation follows a consistent pattern. The CTO is not asking whether the model is capable. They are asking: does this thing bypass the permission model our enterprise contracts depend on? Because if it does, even once, even in a subtle edge case, the trust built with their largest customers over years is at risk in a single incident. The cost is not just the incident. It is the security questionnaire responses for the next twelve months and the enterprise deal that stalls because someone found the post-mortem.
Three non-negotiables on every SaaS AI assistant build:
Actions execute under the requesting user’s identity. JWT claims define the permission boundary. No shared elevated IAM role. No AI service account with broader access than the human who initiated the request. If you are evaluating Bedrock AgentCore Identity, its custom claims support for multi-tenant environments addresses exactly this requirement at the managed-service layer.
Tenant isolation is enforced at every layer. OpenSearch queries filtered by tenantId. Bedrock Knowledge Bases scoped with metadata filters. Step Functions executions carry tenant context as input. Aurora row-level security as the final guarantee. Isolation is a constraint at every step, not a filter at entry.
Bedrock Guardrails provides model-layer validation on both inputs and outputs. Denied topics, sensitive information filters (PII detection and redaction), content filters for harmful content categories, and Automated Reasoning checks for factual accuracy.
These are not aspirational design goals. They are the things that get tested in the first enterprise security review, and the things that block the deal if they are missing.
Opening the black box
Your CloudWatch dashboards will tell you the Lambda returned a 200. They will not tell you the model proposed the wrong action, that a guardrail fired on a specific query, or that token costs for one tenant are running at six times the expected rate. Traditional Application Performance Monitoring (APM) was designed for deterministic systems. Agentic systems need a different observability model, one that captures the full decision chain.
Every production AI assistant should emit structured log events covering the full model input, guardrail evaluation results, Step Functions execution trace, human override events, per-request token consumption attributed by tenantId, and end-to-end latency broken down by stage.
Implementation note: Amazon Data Firehose ingests the structured log stream. A transformation Lambda normalizes events into a consistent schema. OpenSearch Service (not Serverless: production trace retention requires lifecycle management and snapshot capabilities that Serverless does not support) stores and powers the trace dashboards. When something unexpected happens in production, the answer is an OpenSearch query, not a grep through CloudWatch logs. Teams using Bedrock AgentCore can take advantage of AgentCore Observability, which provides end-to-end execution tracing through CloudWatch with OpenTelemetry (OTEL) compatibility and third-party integrations. The principle is the same: capture the reasoning trace, not just the infrastructure metrics.
Without this, the first time the CTO asks “why did the assistant do that?”, the answer is a shrug and a CloudWatch log search. With the full trace captured, it is a query that returns in seconds.
Once you have that visibility, you can use it to gate rollout. AWS AppConfig manages feature flags and phased deployment: run the assistant in shadow mode first (decisions logged, not executed), then canary to a subset of tenants, with circuit breakers wrapping Amazon Bedrock calls so a model timeout does not cascade into a platform incident.
The compounding return of getting the architecture right once
There is a version of AI adoption where each new assistant feature is a custom integration exercise. The first took four months. The second took three. They share no permission propagation pattern, no telemetry schema, no deployment pipeline. Every new capability is a fresh negotiation with the infrastructure and the security team.
There is another version. The first assistant is slower to ship because the team builds the governance layer, the Step Functions patterns, the observability pipeline, and the CI/CD configuration with rollback confidence baked in. The second assistant reuses all of it. The third is faster still.
For SaaS founders: the competitive moat is not the model. Models are commoditizing faster than anyone expected. The moat is the governed production infrastructure that enterprise procurement teams can sign off on. And that moat deepens with each new feature you ship on top of it.
The difference between those two versions is not talent. It is the decision made in the first sprint about whether to treat the assistant as a feature or as infrastructure.
Build the first assistant as if the second one depends on it. It does.
How VeUP works with SaaS teams on this
VeUP works inside your AWS account: your environment, your data, your team learning the patterns as we build together. We are not a hosted AI platform. We do not ask you to adopt a new vendor relationship or hand over architectural ownership. Everything we produce is yours: the reference architecture, the Step Functions state machine definitions, the telemetry schema, the deployment pipeline.
The Build engagement runs in four phases: Discover (right use case, right constraints), Design (three-layer architecture, IAM model, guardrail configuration), Build (tight iterations in your repository with observability wired in from sprint one), and Validate and Handover (first weeks in production, telemetry read together, runbooks documented).
The second assistant ships faster because of the first. That is the compounding return.
Ready to scope your first production AI assistant?
Most SaaS teams already have a concept waiting: a support automation flow, an admin operations assistant, an insights layer that should be able to act on what it surfaces. What is missing is a concrete plan. Which use case to start with, what the architecture looks like for your specific data model, where the security boundaries sit, and how you explain the permission model to enterprise customers.
Book a 60-minute session with a VeUP SaaS delivery specialist to map and de-risk your first agentic feature, from architecture and guardrails to telemetry.
That session produces a scoping document your team can take directly into sprint planning: a concrete architecture decision record, not a whiteboard sketch.