A practical game plan for SaaS leaders taking agentic AI from prototype to reliable production.
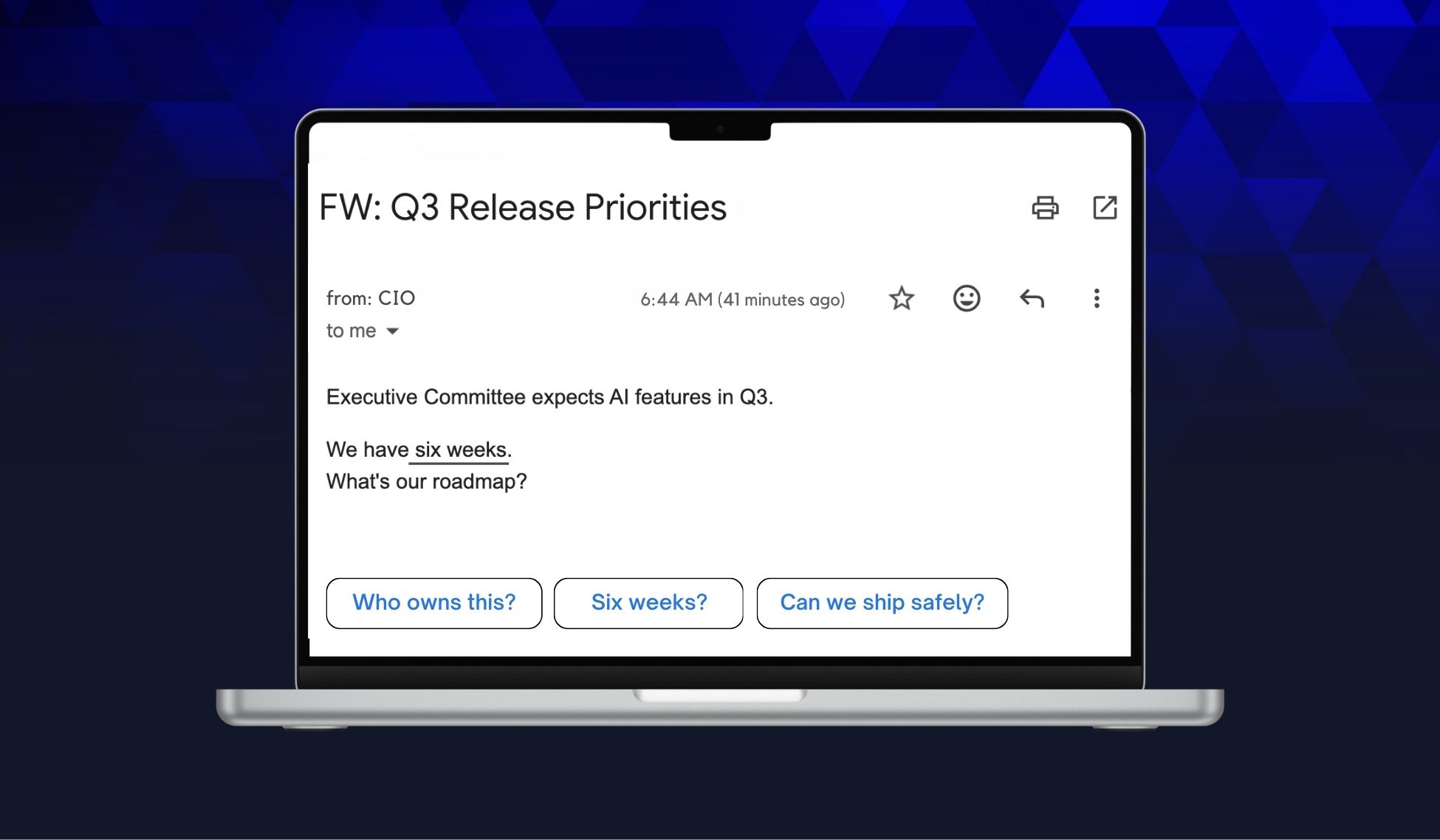
Picture this: your CIO forwards a note from the CEO.
“The Executive Committee wants AI features in our Q3 release. Our competitors are shipping a copilot. What is our AI roadmap?”
You have six weeks.
Whatever ships needs to feel intelligent, respond quickly, stay within budget, and not flood support with incorrect customer data.
Your team knows cloud. A few people have experimented with AI. But no one has shipped an agentic system into production before, especially one that can take actions. Someone becomes the informal AI owner. The infrastructure team is already stretched just keeping the platform stable. And there is no established pattern for turning a promising prototype into a reliable, observable service.
This is where many SaaS teams are right now. Not short on ambition, but short on a production path from “add AI” to “operate AI safely with customers.”
Why Most AI Experiments Never Leave Pilot Stage
Before diving into solutions, we need to understand why the production AI readiness failure rate is so high. In our role with SaaS teams across the industries we work with, we see the same patterns constantly repeated.
The “Shiny Demo” Problem.
Someone builds an AI chatbot in a team codefest. There is a demo and it impresses senior leadership. Months later, it is still running locally on someone’s laptop, connected to production data through a shared API key that was supposed to be temporary.
The Monitoring Vacuum.
Traditional APM tools tell you that an endpoint response is 200. They do not tell you that the confidently stated response contains misinformation about your pricing tiers. Your engineering team ships AI features blind, spending weeks decomposing support requests to understand what went wrong.
The Organization Ownership Void.
Is the AI copilot owned by Product, Engineering, or the “AI Team” which consists of two people who are academically prepared? When the feature generates confused support tickets, nobody clearly understands the demarcation of business or technology capabilities.
The Infrastructure Mismatch.
LLM calls behave nothing like your typical API dependencies. At the system layer, latency is measured in seconds, not milliseconds. Costs scale with token count, not request volume. Rate limits and timeouts remain deterministic. Amazon CloudWatch metrics can tell you when you hit an API throttle limit. At the model layer, output quality is where unpredictability lives. The same prompt can produce confident misinformation one moment and a perfect answer the next. Traditional APM tools track the first layer well. The second layer, what Werner Vogels might call “the behavior you cannot predict”, requires purpose-built telemetry. Your existing circuit breakers and retry logic were designed for a different world.
Agentic features are infrastructure problems as much as product problems. The real work is not choosing which model to use. It is designing the patterns, managing the workloads, and building observability that lets you understand what is happening when customers use your system at scale.
Choosing the Right First Agentic Use Case
Your first agentic feature will teach your organization how to build AI systems. Choose poorly, and you’ll either fail spectacularly or succeed in a way that teaches nothing. This is the AI Black Box problem. Choose the use case well, and you establish patterns that scale.
Narrow Scope
A narrowly scoped agent answers questions about your product documentation. It summarizes activity in a customer’s account. It generates draft responses that a human reviews before sending. The boundary between what the agent can and cannot do is crisp and enforceable, which means when something goes wrong, you can trace exactly where the boundary was crossed.
High Value
The feature solves a real pain point. Your support team spends thirty percent of their time answering the same fifteen questions. Your sales team manually creates proposal documents from scattered data. Pick a use case where success is obvious and measurable. You will need those metrics when the executive team asks for the next AI feature.
Low Risk
Failure does not break trust. A wrong answer in a support chatbot that cites sources and includes a “was this helpful?” button is recoverable. A wrong answer that executes a financial transaction or modifies production data is not. Early mistakes become learning opportunities rather than incidents.
Clear Success Signals
You know what good looks like before you ship. You can define accuracy metrics, measure latency targets, track user override rates, and quantify support ticket deflection. These signals become the telemetry that tells your story from that initial request through to production operations.
The Real AI Lifecycle: Tickets to Telemetry
Let us trace the path from an initial request to a production system with proper observability. At each phase, decisions made early determine what is possible later in operations, in support conversations, and in your ability to explain agent behavior.
Phase 1: Ideation, Selection, and Scoping
The request ticket labeled “Add AI to Product X” needs refinement before anyone writes code. This is where the Tickets to Telemetry journey starts. The scoping exercise should answer: What specific user action does this feature support? What data does the agent need access to? What actions can it take? What happens when it is uncertain? Who reviews the output before it affects anything? How will we know it’s working?
At VeUP, we start engagements with exactly this kind of discovery. Teams often arrive with a solution in mind (“we need an intelligent in-app assistant for our customers”) when what they need is a clear problem statement (“customers cannot find answers to common questions without opening a support request”). The shift from “we have an idea” to “build this thing to solve this problem” changes everything that follows. It is the difference between pressure and poised delivery.
Phase 2: Mapping Data and Permissions
Agentic features consume data and make decisions. You need to know exactly what data flows into the system, what transformations occur, and what permissions govern each step. This mapping is not just architecture documentation. It is the foundation for explaining agent behavior later.
This is where multi-tenancy becomes non-negotiable. When your agent can access customer data, tenant isolation must be absolute. Every query constrained by tenant ID. Every API call is tightly scoped. Every response filtered through permission checks. The architectural pattern: inject tenant context at the entry point, then enforce it at every downstream layer from your AI backend through to your MCP servers and data stores. The decisions you make here about data access directly shape what your telemetry can capture and what your team can explain when a stakeholder asks, “why did the agent do that?”
A quick sidebar on MCP. Model Context Protocol is Anthropic’s open-source specification for connecting AI applications to external systems, including databases, APIs, and business tools. Their analogy: “USB-C for AI.” One protocol replaces a tangle of custom integrations.
Phase 3: Infrastructure Pattern Selection
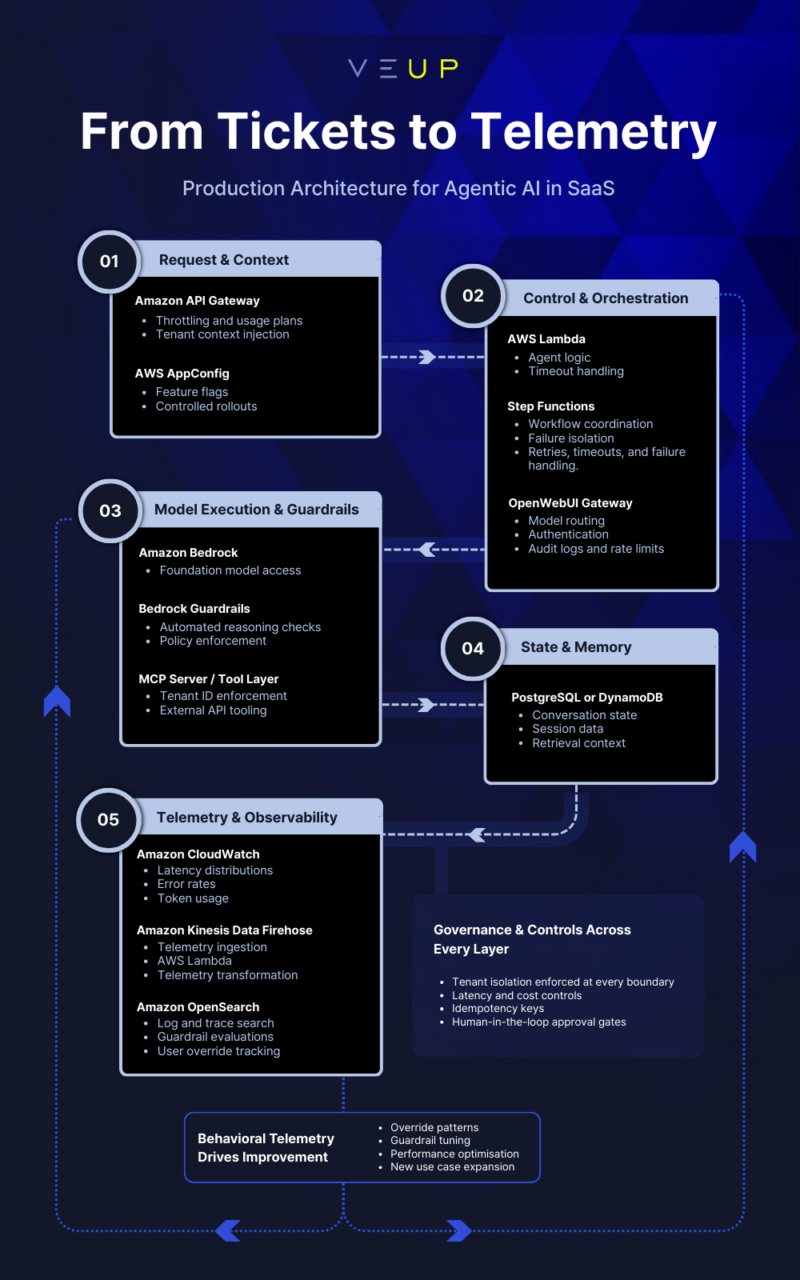
Your infrastructure choices define the blast radius when failures occur. Event-driven and serverless patterns excel at workload isolation. Each Lambda function runs in its own execution environment. When a function processing an AI request times out, that invocation fails, but the failure stays contained. Retry logic can attempt recovery while the rest of your application continues serving customers. The goal is not eliminating failures. It is limiting their reach and making them explainable.
Consider this stack for a typical SaaS agentic feature: Amazon API Gateway handles incoming requests with throttling and usage plans. AWS Lambda functions orchestrate the agent logic. Amazon Bedrock provides the foundation model access with built-in guardrails. A relational database like PostgreSQL handles conversation state. Choose your engine based on retrieval, processing, and storage requirements. Amazon CloudWatch captures the telemetry: latency distributions, token consumption, error rates. For deeper analysis, Amazon OpenSearch Service indexes your logs and traces, enabling fast search across your events.
The resilience fundamentals still apply. This includes timeouts, retries with exponential backoff, circuit breakers, and feature flags for graceful degradation. But LLM calls demand caution. A timed-out request may have completed upstream, and you have paid for tokens you will never see. Use idempotency keys to prevent costly retry amplification and distinguish between transient failures worth retrying and ambiguous timeouts worth investigating. Every infrastructure decision here creates the operational landscape your team could navigate at 2am.
For teams wanting to experiment with model routing while maintaining governance, OpenWebUI provides a useful pattern. It acts as a centralized gateway with authentication, per-user keys, audit logs, and rate limits, letting you route requests to different backends (AWS Bedrock, Groq, Vertex AI) while maintaining visibility and cost control.
Phase 4: Guardrails as First-Class Design
Guardrails are not an afterthought. They are part of the product specification, and they are how you open the black box.
Without guardrails, you will not be able to answer the question, ‘Why did the agent do that?’. When a stakeholder asks, “why did the agent recommend this to a customer?” the answer cannot be “because the model thought it was right.” Guardrails modify that black box into auditable, justifiable behavior.
Define what “bad” looks like before you ship your feature: hallucinated data that contradicts your database; latency exceeding your SLA; runaway API calls that blow through rate limits; unsafe actions that modify data without authorization. For each failure mode, design an intervention. Amazon Bedrock Guardrails provides configurable safeguards that work across foundation models such as Automated Reasoning checks that can validate responses with up to 99% accuracy.
Continuing the theme of explainable behavior, when your engineering lead needs to tell the CIO why the agent suggested a particular action, the guardrail logs show exactly what was permitted, what was blocked, and why. This is how an agent stops being a black box and becomes a system your team can confidently operate and defend.
Human-in-the-loop is not just a safety net; it is a data collection mechanism. When users override agent suggestions, you learn something. When they approve them, you learn something else. This feedback loop is how your AI improves over time, and every override becomes telemetry your support team can reference.
Build explicit boundaries into your agent’s capabilities. Document what constitutes a failure. If it generates a response, it does not send it. If it suggests a configuration change, it doesn’t apply it. The human confirms the action. This sounds limiting, but it is how you build trust with your customers and your operations team.
Phase 5: Telemetry Design
This is where most teams under-invest and where the Tickets to Telemetry journey either completes or falls apart. Traditional logging tells you what happened to your infrastructure. Agentic telemetry tells you what happened to your users and, crucially, why the agent behaved the way it did.
Effective telemetry for AI features captures the full decision chain: inputs including the user query, the context retrieved, and the prompt assembled. Outputs including the model’s response, the reasoning (if available), and confidence scores. Guardrail evaluations showing what was checked and what was triggered; user overrides tracked as first-class events when humans reject or modify agent suggestions. Latency breakdowns showing how long each step took. Cost metrics tracking token consumption, API calls executed, and compute resources used. External calls, presenting what the agent retrieved from knowledge bases or APIs.
This telemetry is what opens the black box. When an engineering lead needs to answer, “why did the agent do that?” it now becomes “here’s the trace” NOT “we’re not sure.”
You need dashboards that answer: What percentage of suggestions are users accepting? Where in the response generation pipeline are we spending the most time? Which queries produce low-confidence responses? How much is this feature costing us per tenant? Plus when something goes wrong, what was the full decision path that led to the outcome?
This telemetry feeds your AI roadmap. Low override rates on a specific query type tell you where to improve. Consistent high latency on one path tells you where to optimize. Guardrail triggers that cluster around certain topics, tell you where your training data has gaps. Usage patterns that emerge tell you what to build next.
For more sophisticated analysis, an observability pipeline starts with Amazon Kinesis Data Firehose as the ingestion layer. Firehose can invoke an AWS Lambda function to handle telemetry data transformation. The transformed data is sent from Lambda to Firehose for buffering and then ships the logs to Amazon OpenSearch where you build queries and surface patterns that matter.
The AI system isn’t “done” when it’s implemented. The real breakthrough is closing the feedback loop faster. When behavioral telemetry flows through your analytics stack, every user session becomes training data for your next iteration.
Organizational Clarity: Who Owns This Thing?
Agentic features create coordination challenges that traditional features do not. Ownership spans the user experience, the telemetry, the operational metrics, and the improvement roadmap. Establish clear ownership before deployment. The product manager defines success criteria and prioritizes improvements. The engineering lead owns the architecture, the deployment pipeline, the operational runbooks and critically, owns the ability to explain agent decisions to stakeholders. The support team has an SOP path for AI-related issues and a direct channel to the engineering owner.
When the support team can trace a customer complaint back through the telemetry to the specific agent decision, and the engineering lead can explain why the guardrails permitted that decision, you’ve completed the journey from ticket to telemetry. The system is no longer a black box. It’s an observable, explainable service your organization can operate with confidence.
If you want to run this lifecycle with less rework, treat it like an engineering discipline, not a one-off feature. Start with a narrowly scoped use case, design guardrails alongside telemetry, and assign an explicit owner before you ship. Here is a simple engagement shape we often use to help teams move from ‘good prototype’ to ‘operable production.’
The VeUP “Build” Engagement Model
At VeUP, we have developed a structured approach to helping SaaS teams ship their agentic features safely. We typically get involved when teams have the pressure to deliver but lack the production AI experience to do so confidently. The shift we create is from “we need to ship something” to “we know exactly what we’re building, how we’ll operate it, and how we’ll explain its behavior.”
Discover
We start by understanding your product, your data architecture, your team’s experience with AI/ML, and your business goals. By the end, we have identified candidate use cases ranked by feasibility and impact, and we have reframed the problem from “add AI” to “solve this specific customer problem.”
Design
We design the technical approach, select the infrastructure patterns, define the telemetry schema, and map out the guardrails. Everything aligns to AWS best practices from the start. The guardrails and telemetry are designed together so that agent behavior is explainable from day one.
Build
This happens in tight iterations. We are working with your team, writing code in your repository, deploying to your infrastructure. Telemetry and dashboard setup happens in parallel. By the time the feature ships, you have visibility. You are not flying blind. Your engineering lead can already explain agent decisions because the observability was designed alongside the feature.
Validate / Handover
Covers the critical first weeks in production. We help interpret the telemetry, tune the guardrails based on real-world behavior, and ensure the handoff to your team is complete. The Tickets to Telemetry journey ends with your team confidently operating the system and able to explain its behavior to anyone who asks.
The Path Forward
SaaS teams are under pressure to “ship AI” quickly, but most fail because they treat agentic features as one-off experiments instead of production workloads with guardrails, observability, and clear ownership. VeUP helps them design and ship their first agentic features as robust, observable services, so they can move fast on AI without sacrificing reliability, customer trust, or roadmap discipline.
Ready to Map your First (or next) Agentic Feature?
The pressure to “add AI” isn’t going away. But the path from pressure to production doesn’t have to be chaotic.
Want a second set of eyes before you ship? Book a 60-minute session with a VeUP Solution Architect. We will help you pressure-test the use case, define guardrails, and sketch a telemetry plan, so you can own the rollout with confidence.